周末了,复习小小暂停一下下,耍一哈CTF()
复习周摸摸鱼,跟虾饺皇的大佬们一起打,拿点贡献度(),下面某些题会存在一些参考成分,有点久没打了,思路有点卡壳了
难一点的GoogleCTF一进去,发现要谷歌账号,直接就下班了
发现比赛平台还开着,比赛地址https://score.wanictf.org/#/challenge
按难度划分,应该是新生赛(官方标的,还是有一定难度的,可能这就是国外的比赛吧),有兴趣可以去看看
直接分解n
from Crypto.Util.number import *n = 317903423385943473062528814030345176720578295695512495346444822768171649361480819163749494400347 e = 65537 enc = 127075137729897107295787718796341877071536678034322988535029776806418266591167534816788125330265 p = [9953162929836910171 , 11771834931016130837 , 12109985960354612149 , 13079524394617385153 , 17129880600534041513 ] phi = 1 for i in p: phi *= i-1 d = inverse(e, phi) print (long_to_bytes(pow (enc, d, n)))
爆破一下key和iv的一位,再校验flag
from Crypto.Cipher import AESfrom os import urandomfrom hashlib import sha256enc = b'\x16\x97,\xa7\xfb_\xf3\x15.\x87jKRaF&"\xb6\xc4x\xf4.K\xd77j\xe5MLI_y\xd96\xf1$\xc5\xa3\x03\x990Q^\xc0\x17M2\x18' flag_hash = 0x6a96111d69e015a07e96dcd141d31e7fc81c4420dbbef75aef5201809093210e while 1 : key = b'the_enc_key_is_' iv = b'my_great_iv_is_' key += urandom(1 ) iv += urandom(1 ) cipher = AES.new(key, AES.MODE_CBC, iv) flag = cipher.decrypt(enc) if b'FLAG' in flag: print (flag) flag = b'FLAG{7h3_f1r57_5t3p_t0_Crypt0!!}' print (sha256(flag).hexdigest()) break
from hashlib import md5from string import printableenc = [...] flag = '' for h in enc: for p in printable: p = ord (p) if int (md5(str (p).encode()).hexdigest(), 16 ) == h: flag += chr (p) print (flag)
题目
import osimport randomfrom hashlib import md5from Crypto.Cipher import AESfrom Crypto.Util.number import long_to_bytes, getPrimeFLAG = os.getenvb(b"FLAG" , b"FAKE{THIS_IS_NOT_THE_FLAG!!!!!!}" ) def encrypt (m: bytes , key: int ) -> bytes : iv = os.urandom(16 ) key = long_to_bytes(key) key = md5(key).digest() cipher = AES.new(key, AES.MODE_CBC, iv=iv) return iv + cipher.encrypt(m) def f (s, p ): u = 0 for i in range (p): u += p - i u *= s u %= p return u p = getPrime(1024 ) s = random.randint(1 , p - 1 ) A = f(s, p) ciphertext = encrypt(FLAG, s).hex () print (f"{p = } " )print (f"{A = } " )print (f"{ciphertext = } " )p = 108159532265181242371960862176089900437183046655107822712736597793129430067645352619047923366465213553080964155205008757015024406041606723580700542617009651237415277095236385696694741342539811786180063943404300498027896890240121098409649537982185247548732754713793214557909539077228488668731016501718242238229 A = 60804426023059829529243916100868813693528686280274100232668009387292986893221484159514697867975996653561494260686110180269479231384753818873838897508257692444056934156009244570713404772622837916262561177765724587140931364577707149626116683828625211736898598854127868638686640564102372517526588283709560663960 ciphertext = '9fb749ef7467a5aff04ec5c751e7dceca4f3386987f252a2fc14a8970ff097a81fcb1a8fbe173465eecb74fb1a843383'
先求s,推导过程中,仿佛梦回高中数列()为方便书写,以下操作均在 Z p ∗ 中进行 为方便书写,以下操作均在Z_{p}^{*}中进行 为 方 便 书 写 , 以 下 操 作 均 在 Z p ∗ 中 进 行
A = p ∗ s p + ( p − 1 ) ∗ s p − 1 + ( p − 2 ) ∗ s p − 2 + . . . + 3 ∗ s 3 + 2 ∗ s 2 + s A=p*s^{p}+(p-1)*s^{p-1}+(p-2)*s^{p-2}+...+3*s^{3}+2*s^{2}+s A = p ∗ s p + ( p − 1 ) ∗ s p − 1 + ( p − 2 ) ∗ s p − 2 + . . . + 3 ∗ s 3 + 2 ∗ s 2 + s
s A = p ∗ s p + 1 + ( p − 1 ) ∗ s p + ( p − 2 ) ∗ s p − 1 + . . . + 3 ∗ s 4 + 2 ∗ s 3 + s 2 sA=p*s^{p+1}+(p-1)*s^{p}+(p-2)*s^{p-1}+...+3*s^{4}+2*s^{3}+s^{2} s A = p ∗ s p + 1 + ( p − 1 ) ∗ s p + ( p − 2 ) ∗ s p − 1 + . . . + 3 ∗ s 4 + 2 ∗ s 3 + s 2
A − s A = − p ∗ s p + 1 + s p + s p − 1 + . . . + s 2 + s = s p + s p − 1 + . . . + s 2 + s = s ∗ ( 1 − s p ) / ( 1 − s ) A-sA=-p*s^{p+1}+s^{p}+s^{p-1}+...+s^{2}+s=s^{p}+s^{p-1}+...+s^{2}+s=s*(1-s^{p})/(1-s) A − s A = − p ∗ s p + 1 + s p + s p − 1 + . . . + s 2 + s = s p + s p − 1 + . . . + s 2 + s = s ∗ ( 1 − s p ) / ( 1 − s )
A ( 1 − s ) 2 = s ∗ ( 1 − s p ) = s − s 2 ,费马小定理 A(1-s)^{2}=s*(1-s^{p})=s-s^{2},费马小定理 A ( 1 − s ) 2 = s ∗ ( 1 − s p ) = s − s 2 , 费 马 小 定 理
( A + 1 ) ∗ s 2 − ( 2 A + 1 ) ∗ s + A = 0 (A+1)*s^{2}-(2A+1)*s+A=0 ( A + 1 ) ∗ s 2 − ( 2 A + 1 ) ∗ s + A = 0
肉眼可见 s = 1 是一个解,由韦达定理可得, 1 ∗ s = A ∗ ( A + 1 ) − 1 肉眼可见s=1是一个解,由韦达定理可得,1*s=A*(A+1)^{-1} 肉 眼 可 见 s = 1 是 一 个 解 , 由 韦 达 定 理 可 得 , 1 ∗ s = A ∗ ( A + 1 ) − 1
return iv + cipher.encrypt(m),注意这段代码,需要把iv和ciphertext给分离出来
from Crypto.Util.number import *from Crypto.Cipher import AESfrom hashlib import md5p = 108159532265181242371960862176089900437183046655107822712736597793129430067645352619047923366465213553080964155205008757015024406041606723580700542617009651237415277095236385696694741342539811786180063943404300498027896890240121098409649537982185247548732754713793214557909539077228488668731016501718242238229 A = 60804426023059829529243916100868813693528686280274100232668009387292986893221484159514697867975996653561494260686110180269479231384753818873838897508257692444056934156009244570713404772622837916262561177765724587140931364577707149626116683828625211736898598854127868638686640564102372517526588283709560663960 iv_cip = long_to_bytes( 0x9fb749ef7467a5aff04ec5c751e7dceca4f3386987f252a2fc14a8970ff097a81fcb1a8fbe173465eecb74fb1a843383 ) ciphertext = iv_cip[16 :] iv = iv_cip[:16 ] s = inverse(A+1 , p)*A % p key = long_to_bytes(s) key = md5(key).digest() cipher = AES.new(key, AES.MODE_CBC, iv=iv) print (cipher.decrypt(ciphertext))
题目
import osfrom Crypto.Util.Padding import *from Crypto.Util.number import *from Crypto.Cipher import AESfrom hashlib import md5def rotl (x, y ): x &= 0xFFFFFFFFFFFFFFFF return ((x << y) | (x >> (64 - y))) & 0xFFFFFFFFFFFFFFFF class MyCipher : def __init__ (self, s0, s1 ): self.X = s0 self.Y = s1 self.mod = 0xFFFFFFFFFFFFFFFF self.BLOCK_SIZE = 8 def get_key_stream (self ): s0 = self.X s1 = self.Y sum = (s0 + s1) & self.mod s1 ^= s0 key = [] for _ in range (8 ): key.append(sum & 0xFF ) sum >>= 8 self.X = (rotl(s0, 24 ) ^ s1 ^ (s1 << 16 )) & self.mod self.Y = rotl(s1, 37 ) & self.mod return key def encrypt (self, pt: bytes ): ct = b'' for i in range (0 , len (pt), self.BLOCK_SIZE): ct += long_to_bytes(self.X) key = self.get_key_stream() block = pt[i:i+self.BLOCK_SIZE] ct += bytes ([block[j] ^ key[j] for j in range (len (block))]) return ct s0 = bytes_to_long(os.urandom(8 )) s1 = bytes_to_long(os.urandom(8 )) cipher = MyCipher(s0, s1) secret = b'FLAG{' +b'*' *19 +b'}' pt = pad(secret, 8 ) ct = cipher.encrypt(pt) print (f'ct = {ct} ' )ct = b'"G:F\xfe\x8f\xb0<O\xc0\x91\xc8\xa6\x96\xc5\xf7N\xc7n\xaf8\x1c,\xcb\xebY<z\xd7\xd8\xc0-\x08\x8d\xe9\x9e\xd8\xa51\xa8\xfbp\x8f\xd4\x13\xf5m\x8f\x02\xa3\xa9\x9e\xb7\xbb\xaf\xbd\xb9\xdf&Y3\xf3\x80\xb8'
是个流密码,一堆异或,但没怎么搞懂加密的逻辑(想反推),有空再细细钻研一下吧
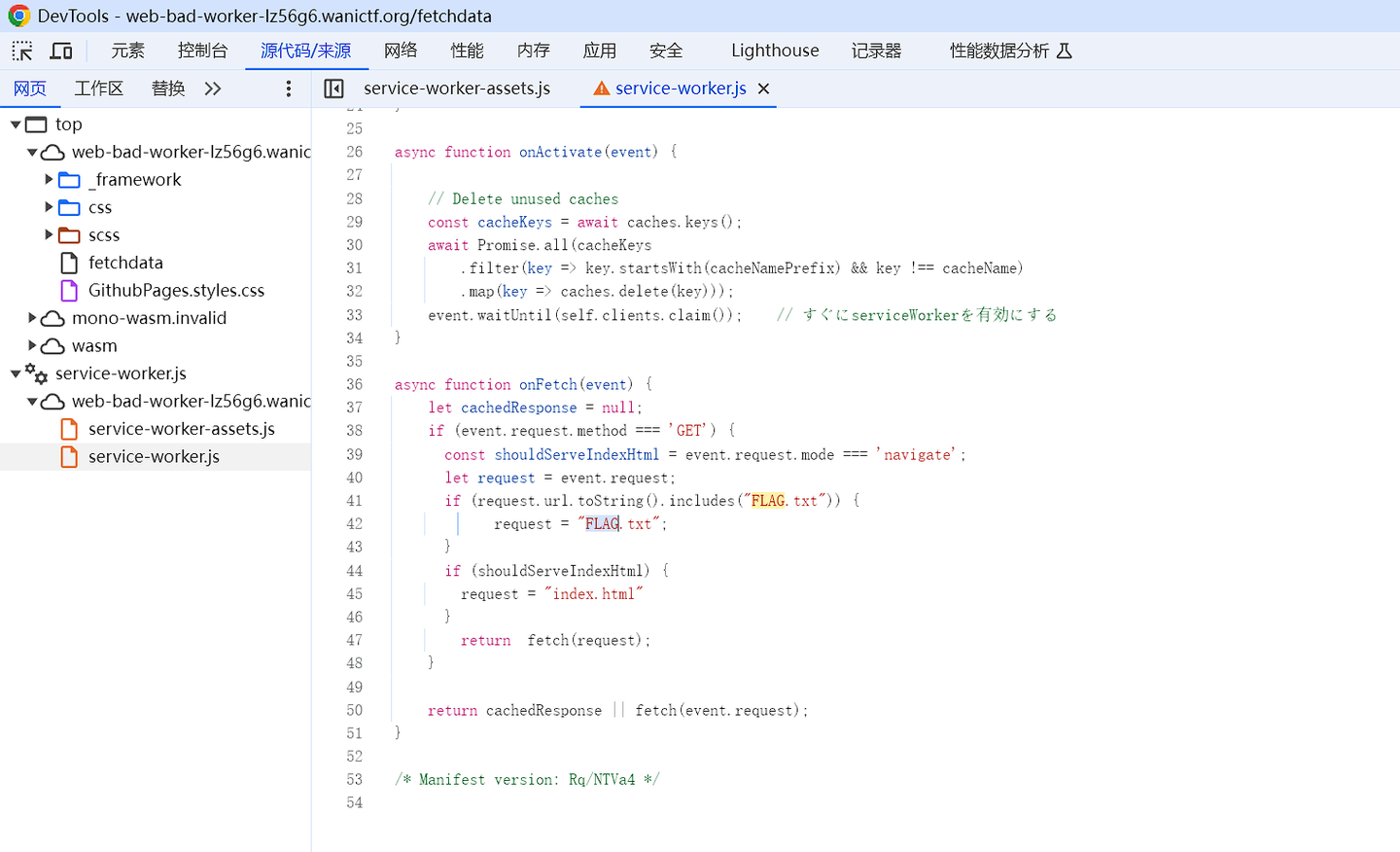
题目里的谷歌浏览器算不算一个提示呢FLAG.txt的js文件,但是火狐这边没找到源代码捏,直接切换谷歌浏览器,把输出的FLAG.txt文件替换上去,保存,再点击按钮获取flag
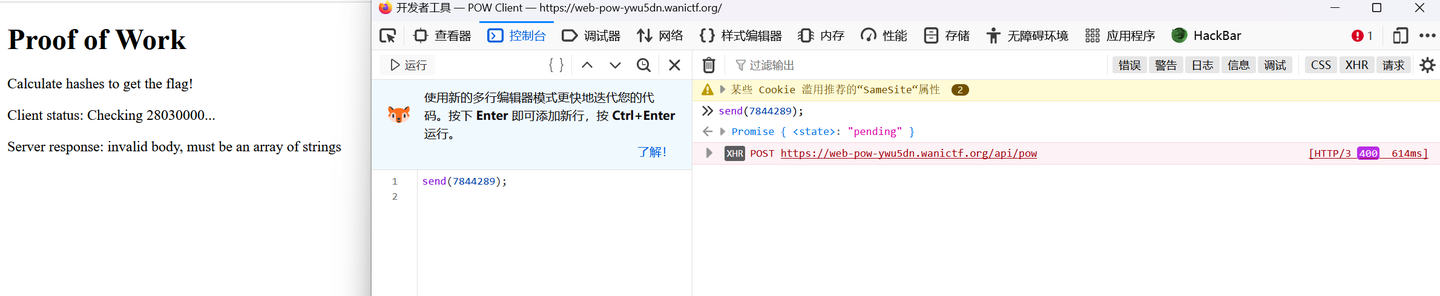
Proof of Work ,看js代码好像是SHA-256的比较(?)
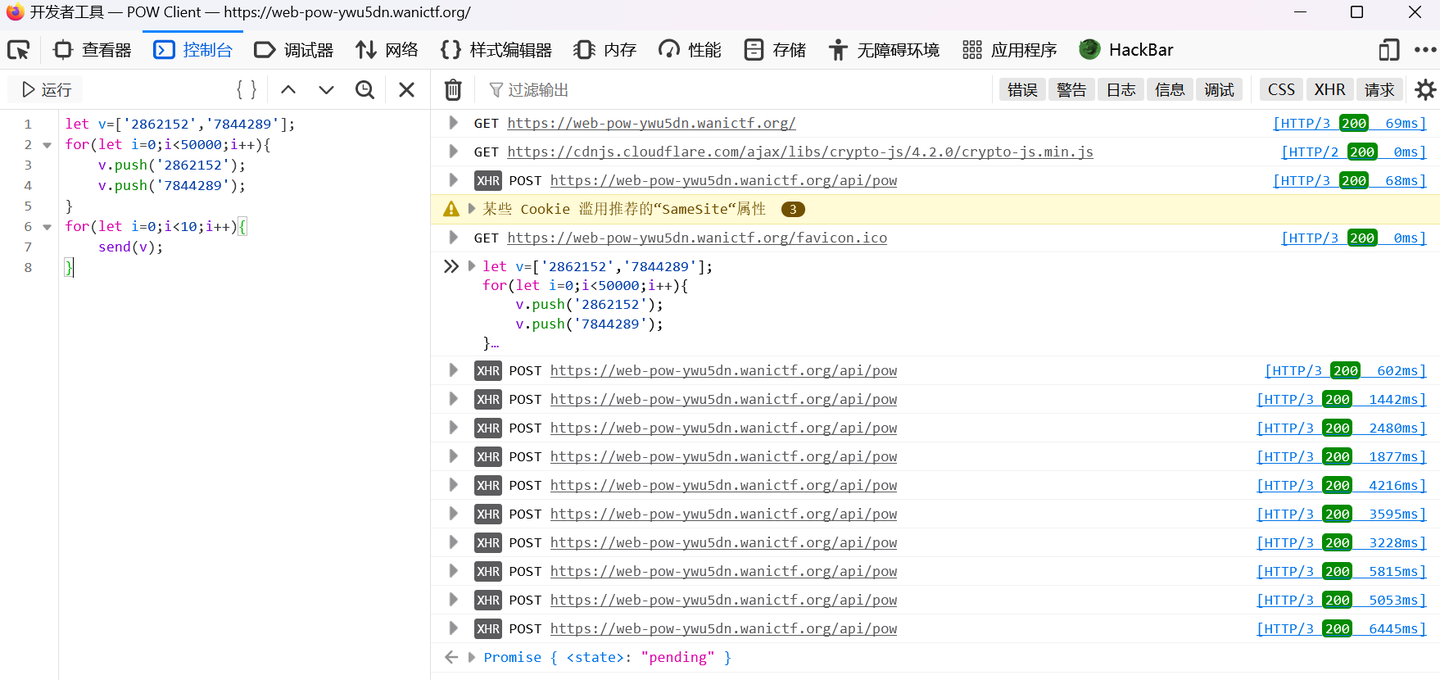
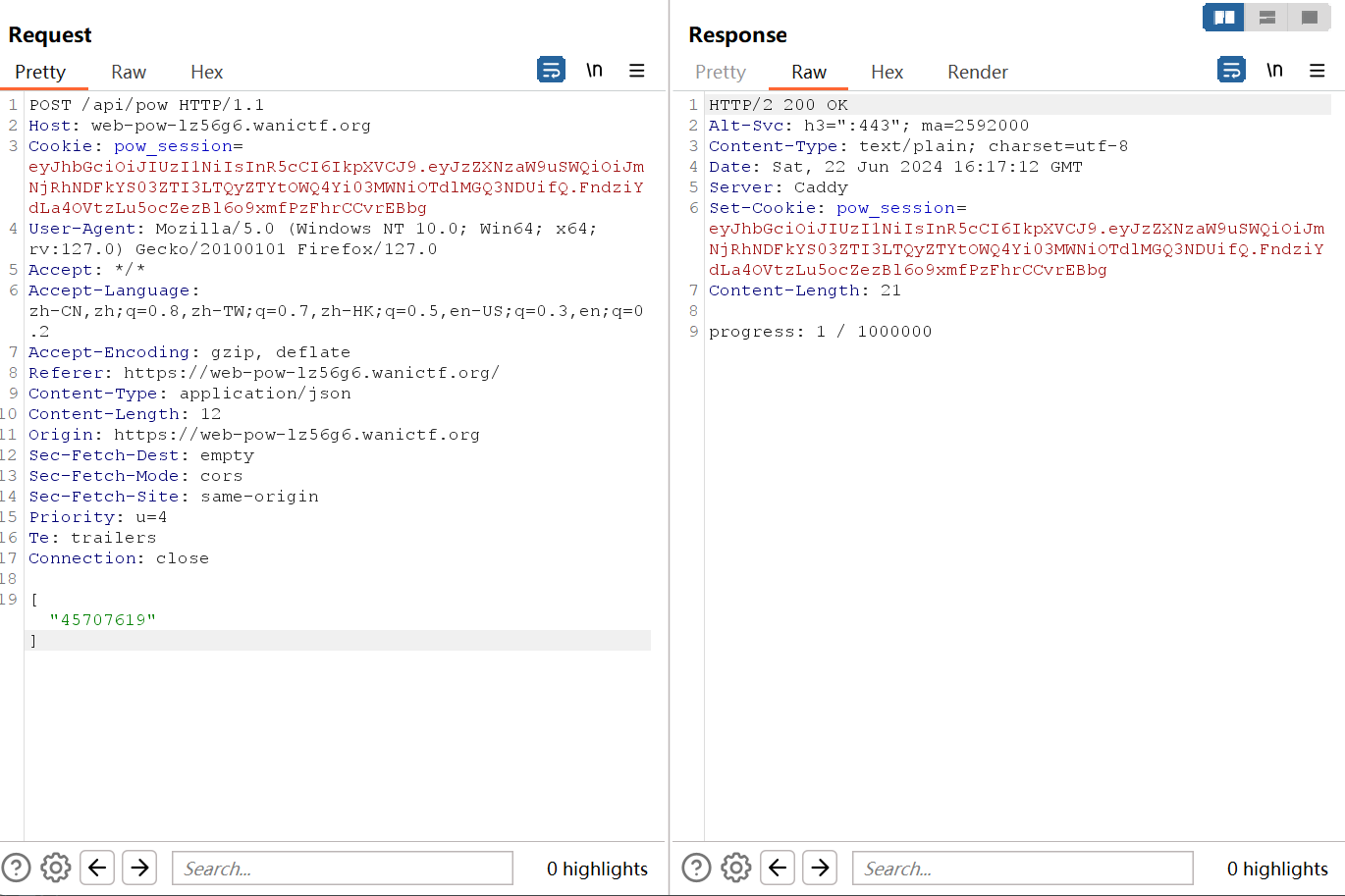
页面数字在不断增大,然后抓包,查看Http History,发现有令progress增加的字符数组,应该是符合条件了,如['2862152']和['7844289']等,抓包发送的话,手动连续发相同的包,一开始确实progress在增加,说明重复也是OK的,但后面发现不能这样做,会出现rate limit exceeded,应该是存在发包数量限制,短时间内发10个这样倒是没什么问题,总共要100万,这样一个数组都要10万了,手动生成是不可能的,可以借助一下控制台生成
从我们截获的包也知道,得发送字符串数组
可以在控制台验证一下
发现确实是要字符数组
let v=['2862152' ,'7844289' ];for (let i=0 ;i<50000 ;i++){ v.push ('2862152' ); v.push ('7844289' ); } for (let i=0 ;i<10 ;i++){ send (v); }
题目里面翻到的js代码
const contentserver = 'web-one-day-one-letter-content-lz56g6.wanictf.org' const timeserver = 'web-one-day-one-letter-time-lz56g6.wanictf.org' function getTime ( return new Promise ((resolve ) => { const xhr = new XMLHttpRequest (); xhr.open ('GET' , 'https://' + timeserver); xhr.send (); xhr.onload = () => { if (xhr.readyState == 4 && xhr.status == 200 ) { resolve (JSON .parse (xhr.response )) } }; }); } function getContent ( return new Promise ((resolve ) => { getTime () .then ((time_info ) => { const xhr = new XMLHttpRequest (); xhr.open ('POST' , 'https://' + contentserver); xhr.setRequestHeader ('Content-Type' , 'application/json' ) const body = { timestamp : time_info['timestamp' ], signature : time_info['signature' ], timeserver : timeserver }; xhr.send (JSON .stringify (body)); xhr.onload = () => { if (xhr.readyState == 4 && xhr.status == 200 ) { resolve (xhr.response ); } }; }); }); } function initialize ( getContent () .then ((content ) => { document .getElementById ('content' ).innerHTML = content; }); } initialize ();
FLAG{l???????????},一天解锁一个flag位timeserver的时间,因为timeserver可控,所以可以构造恶意的timeserver来伪造我们想要的timestamp
附件里面给了timeserver的配置文件,但得自己配一个证书,可能还需要一个域名(大佬文档里写的),然后利用题目里面的js代码,请求content-server,大概过程就是这样的
from http import HTTPStatusfrom http.server import BaseHTTPRequestHandler, HTTPServerimport jsonimport timefrom Crypto.Hash import SHA256from Crypto.PublicKey import ECCfrom Crypto.Signature import DSSkey = ECC.generate(curve='p256' ) pubkey = key.public_key().export_key(format ='PEM' ) class HTTPRequestHandler (BaseHTTPRequestHandler ): def do_GET (self ): if self.path == '/pubkey' : self.send_response(HTTPStatus.OK) self.send_header('Content-Type' , 'text/plain; charset=utf-8' ) self.send_header('Access-Control-Allow-Origin' , '*' ) self.end_headers() res_body = pubkey self.wfile.write(res_body.encode('utf-8' )) self.requestline else : second=int (time.time())%60 timestamp = str (int (time.time())).encode('utf-8' ) h = SHA256.new(timestamp) signer = DSS.new(key, 'fips-186-3' ) signature = signer.sign(h) self.send_response(HTTPStatus.OK) self.send_header('Content-Type' , 'text/json; charset=utf-8' ) self.send_header('Access-Control-Allow-Origin' , '*' ) self.end_headers() res_body = json.dumps({'timestamp' : timestamp.decode('utf-8' ), 'signature' : signature.hex ()}) self.wfile.write(res_body.encode('utf-8' )) andler = HTTPRequestHandler ttpd = HTTPServer(('' , 5001 ), andler) ttpd.socket = ssl.wrap_socket(httpd.socket,certfile='cert.pem' ,keyfile='key.pem' ,server_side=True ) ttpd.serve_forever()
大佬写的包括证书配置的脚步
function getTime ( return new Promise ((resolve ) => { const xhr = new XMLHttpRequest (); xhr.open ('GET' , 'https://' + 'server.com' ); xhr.send (); xhr.onload = () => { if (xhr.readyState == 4 && xhr.status == 200 ) { resolve (JSON .parse (xhr.response )) } }; }); } function getContent ( return new Promise ((resolve ) => { getTime () .then ((time_info ) => { const xhr = new XMLHttpRequest (); xhr.open ('POST' , 'https://' + contentserver); xhr.setRequestHeader ('Content-Type' , 'application/json' ) const body = { timestamp : time_info['timestamp' ], signature : time_info['signature' ], timeserver : 'server.com' }; xhr.send (JSON .stringify (body)); xhr.onload = () => { if (xhr.readyState == 4 && xhr.status == 200 ) { resolve (xhr.response ); } }; }); }); } initialize ();
这个给了附件,应该可以本地起docker,但好像没什么思路……
7zip打开,就直接逃课了
在线二维码工具https://merri.cx/qrazybox/ Reed-Solomon Decoder 进行decode
下载bmc-toolshttps://github.com/ANSSI-FR/bmc-tools kali上面了,还得新建cache文件夹
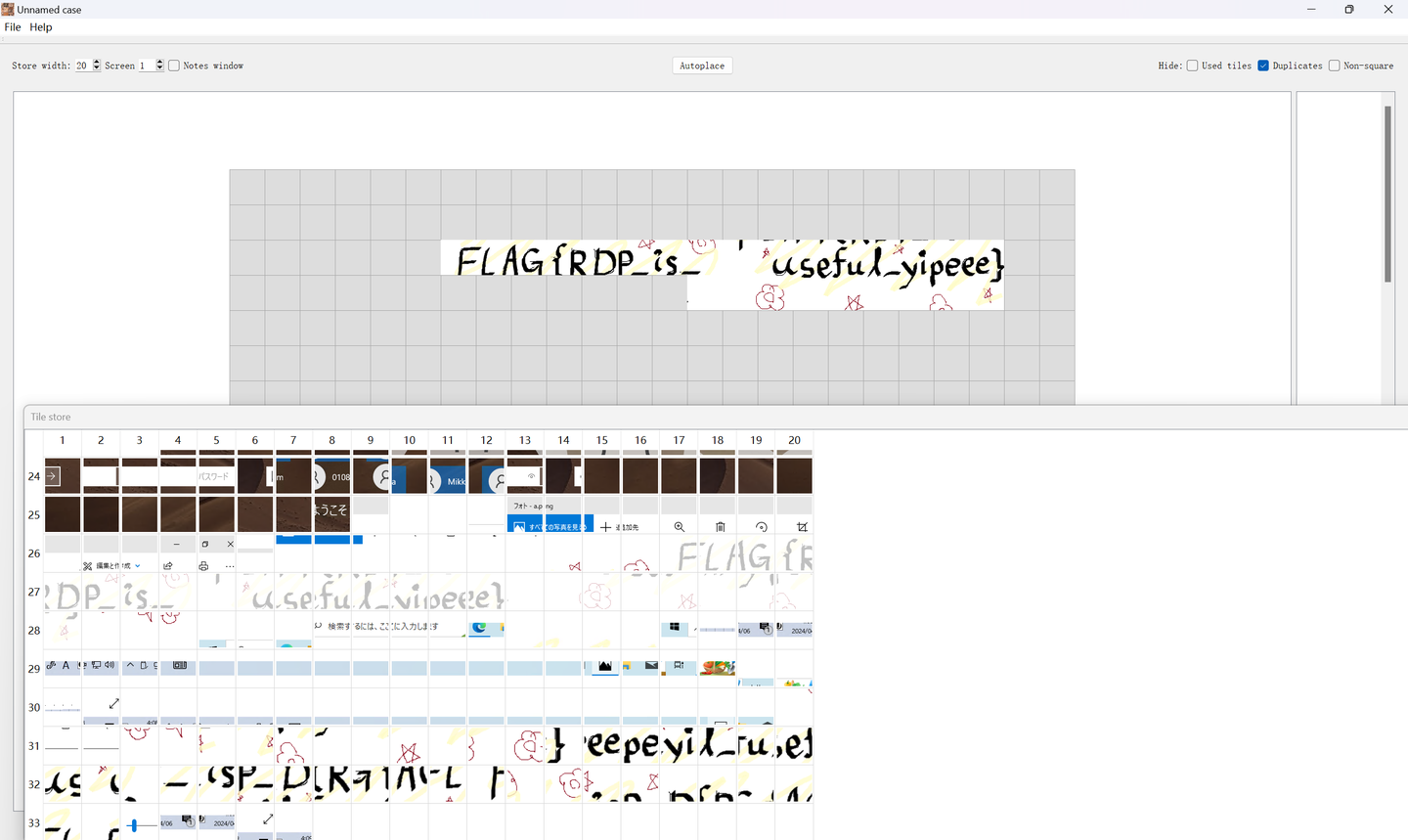
bin格式的RDP Bitmap Chache解析python3 bmc-tools.py -s Cache_chal.bin -d cache
这题算良心,虽然650张图片,但是有效的flag图片都集中在一起了,而且比较容易看出来,然后再稍微猜测一下就可以出了FLAG{RDP_is_useful_yipeee}
看这flag有RDP,后面一翻https://blog.csdn.net/liu_si_yan/article/details/129951463 一种RDP缓存文件(*.bmc)取证分析方法 ,这里是bin格式RdpCacheStitcher下载 https://github.com/BSI-Bund/RdpCacheStitcher
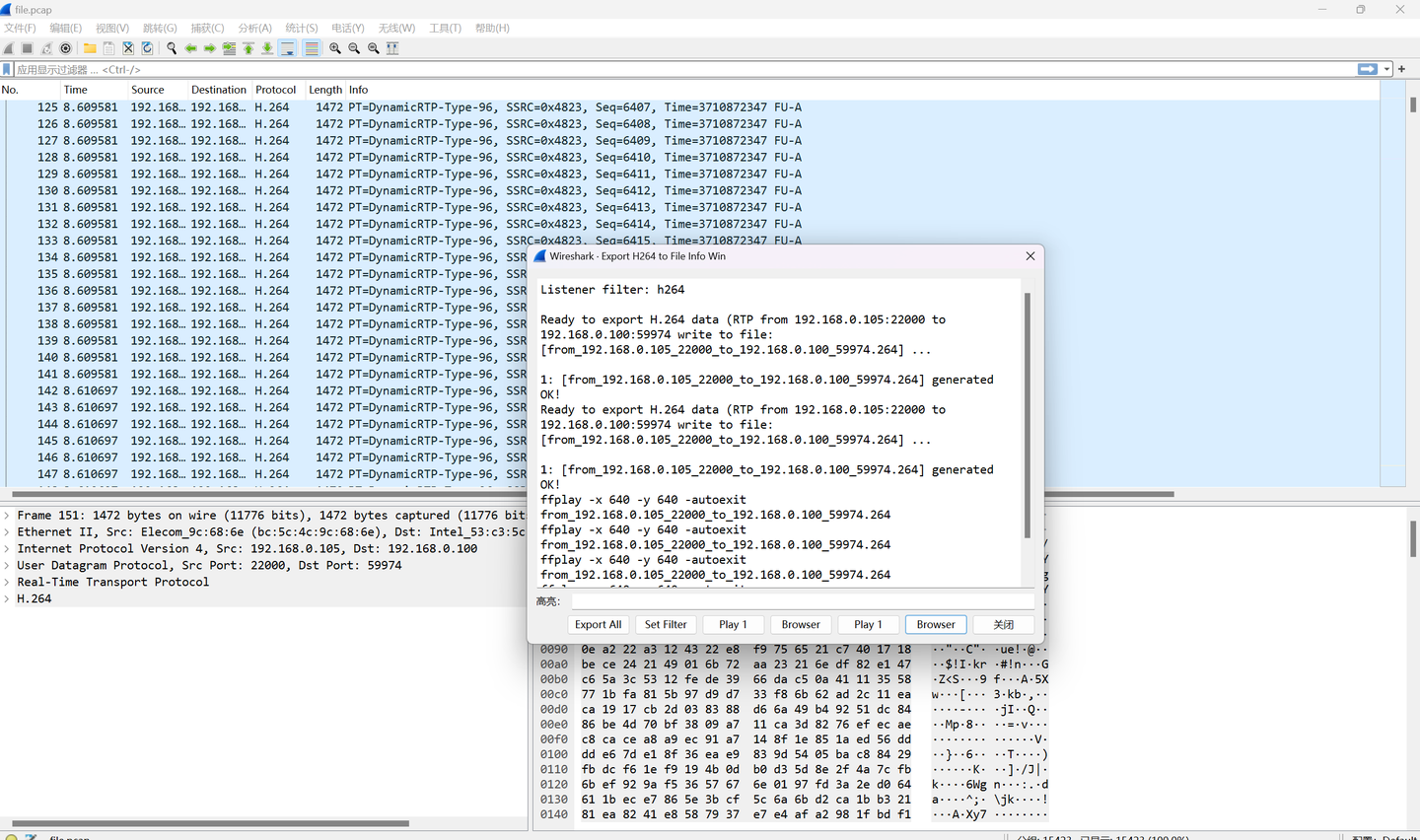
H264流量提取,很多博客都有讲,payload设为96https://github.com/hongch911/WiresharkPlugin VLC进行转换,还是不行,过程应该是正确了的
分辨率10*10,也才100bits,图片大小44kb,我们知道1kb=1024bits,说明肯定藏东西了,binwalk没分离出东西,拖入虚拟机也正常(把jpg当png处理了,笑嘻了,别学),一般的隐写也没见得,好像一般的思路就没了,而且图片像素这么小,肯定是跟这个有关系的,后面才发现jpg和png的宽高显示错误是不一样的,png是可以通过计算crc值或者拖入虚拟机查看报错来确认宽高是否有问题,jpg不能这样做,只能学学格式改改宽高了
010打开,起始头FF C0,00 11 08三个字节,高宽后四个字节,00 0A 00 0A00 9F 00 9F可以正常显示
nc直接连,15+1=0x10
import syssys.setrecursionlimit(10000000 ) (lambda _0: _0(input ))(lambda _1: (lambda _2: _2('Enter the flag: ' ))(lambda _3: (lambda _4: _4(_1(_3)))(lambda _5: (lambda _6: _6('' .join))(lambda _7: (lambda _8: _8(lambda _9: _7((chr (ord (c) + 12 ) for c in _9))))(lambda _10: (lambda _11: _11('' .join))(lambda _12: (lambda _13: _13((chr (ord (c) - 3 ) for c in _10(_5))))(lambda _14: (lambda _15: _15(_12(_14)))(lambda _16: (lambda _17: _17('' .join))(lambda _18: (lambda _19: _19(lambda _20: _18((chr (123 ^ ord (c)) for c in _20))))(lambda _21: (lambda _22: _22('' .join))(lambda _23: (lambda _24: _24((_21(c) for c in _16)))(lambda _25: (lambda _26: _26(_23(_25)))(lambda _27: (lambda _28: _28('16_10_13_x_6t_4_1o_9_1j_7_9_1j_1o_3_6_c_1o_6r' )) (lambda _29: (lambda _30: _30('' .join))(lambda _31: (lambda _32: _32((chr (int (c, 36 ) + 10 ) for c in _29.split('_' ))))(lambda _33: (lambda _34: _34(_31(_33)))(lambda _35: (lambda _36: _36(lambda _37: lambda _38: _37 == _38))(lambda _39: (lambda _40: _40(print ))(lambda _41: (lambda _42: _42(_39))(lambda _43: (lambda _44: _44(_27))(lambda _45: (lambda _46: _46(_43(_45)))(lambda _47: (lambda _48: _48(_35))(lambda _49: (lambda _50: _50(_47(_49)))(lambda _51: (lambda _52: _52('Correct FLAG!' ))(lambda _53: (lambda _54: _54('Incorrect' ))(lambda _55: (lambda _56: _56(_41(_53 if _51 else _55)))(lambda _57: lambda _58: _58)))))))))))))))))))))))))))
丢给GPT
def reverse_step_5 (s ): return '' .join(chr (int (c, 36 ) + 10 ) for c in s.split('_' )) def reverse_step_4 (s ): return '' .join(chr (123 ^ ord (c)) for c in s) def reverse_step_3 (s ): return '' .join(chr (ord (c) + 3 ) for c in s) def reverse_step_2 (s ): return '' .join(chr (ord (c) - 12 ) for c in s) def reverse_step_1 (s ): return '' .join(s) def decode_flag (encoded_flag ): step_5 = reverse_step_5(encoded_flag) step_4 = reverse_step_4(step_5) step_3 = reverse_step_3(step_4) step_2 = reverse_step_2(step_3) step_1 = reverse_step_1(step_2) return step_1 encoded_flag = '16_10_13_x_6t_4_1o_9_1j_7_9_1j_1o_3_6_c_1o_6r' decoded_flag = decode_flag(encoded_flag) print ("解密后的flag:" , decoded_flag)
from flask import *import subprocessapp = Flask(__name__) @app.route("/" def get (): return render_template("index.tmpl" ) @app.route("/" , methods=["POST" ] def post (): filter = request.form["filter" ] print ("[i] filter :" , filter ) if len (filter ) >= 9 : return render_template("index.tmpl" , error="Filter is too long" ) if ";" in filter or "|" in filter or "&" in filter : return render_template("index.tmpl" , error="Filter contains invalid character" ) command = "jq '{}' test.json" .format (filter ) ret = subprocess.run( command, shell=True , stdout=subprocess.PIPE, stderr=subprocess.PIPE, encoding="utf-8" , ) return render_template("index.tmpl" , contents=ret.stdout, error=ret.stderr) if __name__ == "__main__" : app.run(host="0.0.0.0" , port=8000 , debug=True )
考察JQ,关键代码command = "jq '{}' test.json".format(filter);|&
jq [ options] <jq filter> [ file...] jq [ options] --args <jq filter> [ strings...] jq [ options] --jsonargs <jq filter> [ JSON_TEXTS...]
选项
-c 紧凑而不是漂亮的输出; -n 使用`null -e 根据输出设置退出状态代码; -s 将所有输入读取(吸取)到数组中;应用过滤器; -r 输出原始字符串,而不是JSON文本; -R 读取原始字符串,而不是JSON文本; -C 为JSON着色; -M 单色(不要为JSON着色); -S 在输出上排序对象的键; --tab 使用制表符进行缩进; --arg a v 将变量$a设置为value<v>; --argjson a v 将变量$a设置为JSON value<v>; --slurpfile a f 将变量$a设置为从<f>读取的JSON文本数组; --rawfile a f 将变量$a设置为包含<f>内容的字符串; --args 其余参数是字符串参数,而不是文件; --jsonargs 其余的参数是JSON参数,而不是文件; -- 终止参数处理;
奇怪,输入-r或者-R都没有反应,难道是因为读的是test.json?' -R /*',注意前面有空格,单引号闭合jq '' -R /*'' test.json